My colleague, Emily Kilcer, and I published an article about our multi-year effort to better steward electronic theses and dissertations (ETDs) at UAlbany. This post is a supplement that dives deeper into the technical details.
The Libraries have long been responsible for preserving master’s theses and doctoral dissertations from students, and from the 1960s to 2008 preservation copies were bound and preserved physically in the University Archives. In 2008 the Graduate School switched to born-digital submissions using ProQuest’s ETD administrator which charged students fees for baseline and (usually unnecessary) optional services. As a graduate student, I paid ProQuest to make my thesis openly available without a paywall.1 Currently this fee is $95, but I remember it being more than that, which might just tell you how significant that is for a graduate student. Around the same time I was graduating in 2013, the University Libraries started an open access repository with similar affordances. So, we were requiring students to pay a vendor for a service that we were also providing for free. The Libraries were only given a microfilm copy and ProQuest’s subscription service monopolized managed access.
Basically, we fixed it and now students submit ETDs directly through our OA repository. It took about 5 years. It revealed a lot of organizational deficiencies. It was a whole thing. If you’re a glutton for resource cuts causing dysfunctional organizational communication, you’ll be able to read about it soon. In writing the article, we edited out a bunch of more technical details on how we’re managing ETDs that some reviewers valued to make it more manageable as a journal article.
Transferring ETDs
We learned that ProQuest regularly works with organizations to provide born-digital copies of ETDs by pushing files to a file transfer protocol (FTP) server. Our University IT had existing FTP servers, and they were able to quickly set up an account and provide credentials for ProQuest to push to, and to automatically save transferred ETD packages to the University’s virtualized network file share. Libraries Systems would then be able to provide access to this folder share to anyone who needed it. This was set up relatively quickly, and within two months of the first workflow meeting, the Libraries received copies of every ETD submitted through ProQuest since 2008, as well as ongoing submissions. Each package was a ZIP file containing a PDF of the text, an XML metadata file, and any supplemental materials. While this was not an ideal digital preservation program, it was a major improvement over microfilm copies.
Automating ETD Processing
Figure 3 Initial ProQuest-first ETD workflow
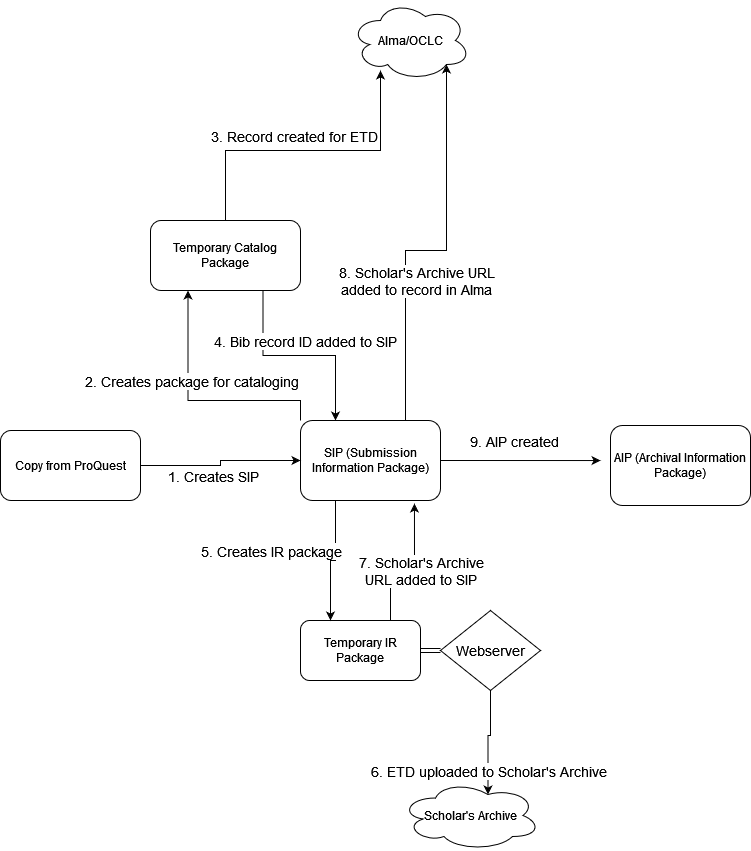
While the Libraries had quickly set up a process to receive ETD submissions from ProQuest, these ETD packages had significant limitations. New packages appeared periodically without a regular schedule. To kick off an automated workflow, this required an additional step to detect when files appeared, move a copy to preservation storage, and notify the cataloger that it was ready for cataloging. The XML metadata file in the package also only contained the information entered by both the authors and the Graduate School during the initial submission. ProQuest later catalogued each ETD and added them to the PQDT Global database, but that metadata only appeared online in the database after submission months later at an inconsistent interval. At that stage, ProQuest also added an identifier to the ETD that UAlbany catalogers had historically used as the primary identifier for the work. This same identifier was also used in the URL to the work in PQDT Global, so it was also necessary to automate the creation of an access link to PQDT Global within the library catalog. This identifier was missing in the XML metadata in the ETD package. To continue this process, cataloging still “kicked off” when the preservation microfilm copy for an ETD arrived at the cataloger’s office. By then the ETD was typically present in PQDT Global with the primary identifier included and the cataloger could create a full MARC record in the local catalog. We asked ProQuest whether the ETD packages could be sent later in the process and the primary identifier could be included, but we did not receive a clear answer and we were not able to follow up as the project stalled due to staff leave and, well, a pandemic.
When work on the ETDs initiative rebooted in Fall 2020, the group made more progress on workflow development. The first workflow design prioritized preservation of the born-digital ETDs, following the Open Archival Information System (OAIS) Reference Model in spirit. Here, the ETD package provided by ProQuest would act as a Submission Information Package (SIP), and the first step after receipt would be the creation of an Archival Information Package (AIP) for preservation. Our AIP for each ETD would follow the Bagit specification. We created a basic Python library that extended bagit-python and contained common code that would package each ZIP file into a “bag” while parsing the included XML metadata files and storing important metadata more accessibly in bag-info.txt files. We created a folder share for these packages where Libraries staff would have read-only access, and a processing server would be the only “user” with access to create and edit AIPs. There is geographic redundancy for this storage on another SUNY system campus, and a concurrent process in Special Collections is developing additional cloud storage redundancy. This pile of bags on access-managed storage with redundancy is “good enough” digital preservation considering our needs and available resources.
During this same burst of work from Fall 2020 to Spring 2021, we also discovered a second major systems barrier for the project: the library catalog (cue evil sound effect). This was the system of record for all bibliographic metadata within the libraries. The Libraries had recently completed a multiyear migration to Alma that incorporated a SUNY system-wide catalog. This effort was seen as an unmitigated success for the Libraries. Since the ETD packages we received from ProQuest contained an XML metadata file, practitioners from Libraries Systems and the University Archives hoped to use this existing data to start a new catalog record similar to workflows they had developed for archival materials using ArchivesSpace, which is designed to service integrations over APIs. The group had little experience working with cataloging systems. While Alma had an open API that could be used to create an initial or “stub” record, the cataloger primarily worked in OCLC Connexion Client. To edit this initial record, it would have to essentially be published by OCLC and downloaded to Connexion Client, a process that could take about a day. Even if we were unconcerned with publishing a problematic initial record, there was no easy way to notify the cataloger that an ETD had been received and was ready for cataloging. The group then investigated the Connexion Client offline Local Save File to see if the initial record could be stored there for the cataloger to edit and publish. The Local Save File is essentially a Microsoft Access database.2 This approach would automatically create an initial record in Connextion Client which the Cataloger would then update and publish to OCLC and Alma. However, after spending some months investigating this, the project team did not find any viable library for editing older Microsoft Access database files. This step remained an open issue and the project stalled again though much of 2021.
The ETD effort rebooted again in December 2021. There was some turnover in the team by this point due to retirements and other staff loss, including the ProQuest liaison role. All the open roles were quickly filled by other colleagues, demonstrating interest in and value for the project. From December 2021 to Summer 2022, the project team met regularly but made inconsistent progress. We were finally able to confirm that ProQuest would not be able to provide ETDs after cataloging or include the primary identifier that the Libraries had historically used. We were also told that the baseline $26 fee that ProQuest charged authors was not for microfilming but was a service fee for the use of ETD Administrator to process ETD submissions. Since there was no ProQuest ETD Administrator contract with the Libraries in place, we felt we had no option to negotiate this. I later found and online fee schedule listing a $26 fee for microfilm while doing article research, so I suspect our contacts were just providing inconsistent information and we could have removed the fee if we really pressed.
With the lack of progress on developing an ongoing workflow for newly submitted ETDs, some new perspectives on the group, and desire for some tangible progress, the group decided to focus on migrating the 2008-2021 ETDs to our Institutional Repository (IR) first and return to the current ETDs in the future. The project team developed python scripts that combined the original submission metadata from the ProQuest export packages with Library catalog records using the Alma API, as the catalog records contained higher-quality metadata than the original author submissions. We were able to connect these records for most authors by matching the author and title fields. For a few hundred remaining ETDs where the titles and authors were not exact matches, we were able to use the fuzzywuzzy library to fuzzy match titles.
We did some typical data cleanup to make fields more consistent. The department field benefited from the Graduate School’s input which contextualized the treatment of interdisciplinary programs and other local situations that created data inconsistencies. This field became “College/Department/Program,” which, while imprecise, was what both users and the Graduate School were using and expecting in practice.
The only process that required substantial manual effort was mapping ProQuest’s standard subject categories to the Digital Commons standard Disciplines taxonomy. These taxonomies were not customizable and had inconsistencies that required a human to do some semantic mapping, such as converting “Education finance” to “Education: Education Economics.” Instead of going one-by-one through over 3,000 ETDs for this, we used a script to extract only the unique ProQuest disciplines to a spreadsheet for mapping. Since there were only 331 unique values, the cataloger on the project team was able to do this manually. These scripts also parsed embargo information from the Graduate School’s export spreadsheet and a spreadsheet of opt-outs using openpyxl (2022). For embargoed ETDs, we migrated metadata for the item, but not the full text PDF, which would only be available from the preservation copy on request after review.
Like every instance of Digital Commons, our IR had a batch upload feature that accepted either XML or older binary Microsoft Excel files (.xls). The project team chose the spreadsheet option, as that allowed both automated and manual interventions, and wrote a final python script to format the data for the IR and write an .xls file using the xlwt library, which, while deprecated, was still effective. This process also required a webserver, as our IR only accepted an accessible URL in the spreadsheet for each PDF file. The same python script also copied the relevant PDF for each ETD to the webserver as it created the .xls file. The webserver was configured to only accept requests from the IR’s IP address, so embargoed ETDs could be added without exposing them publicly. With the correct embargo metadata our IR will automatically make these copies accessible when the embargo expires. All the scripts we used should be available in a Github repo.
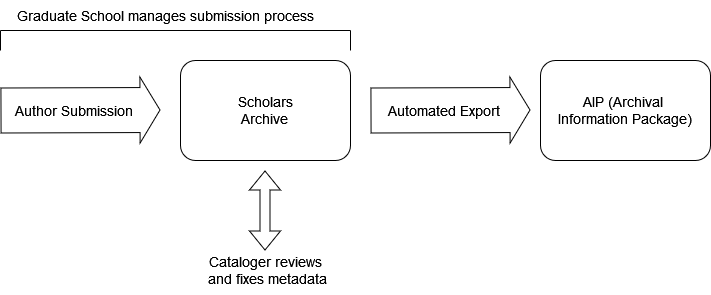
After much organizational back-and-forth, we decided to stop using the ProQuest ETD administrator and have students submit directly through our IR. This had multiple benefits, as it would greatly simplify how the Libraries managed ETDs. Instead of trying to tie together multiple systems in one automated workflow, one system would manage the process. Unless there were approved embargos, ETDs would also immediately be made freely available without any subscription, institutional affiliation, or $95 fee. A separate process will use the Digital Commons API to periodically download copies of new submissions and package them into our preservation storage. We had discussed this option near the start of the project, but decision makers were not ready to make the switch. Our article discusses this more, but our organizational issues meant that we kind of had to fail first before taking the simpler option that was initially viewed as much more of a risk.
Figure 4 Implemented IR-first ETD workflow
Notes
-
I don’t recommend you read it as It’s a bit embarrassing. If you are interested, I recommend Kariann Akemi Yokota’s Unbecoming British: How Revolutionary America Became a Postcolonial Nation. The first chapter in particular uses much of the same source material that I looked at with similar methods and a similar lens but is infinitely better than anything I could do. There’s a good reason I’m not a professional historian. ↩
-
Rebecca B. French, “Direct Database Access to OCLC Connexion’s Local Save File,” Code4Lib Journal Issue 38 (October 18, 2017). ↩